Ripasso di C
Contents
Ripasso di C¶
0.1 Introduzione¶

0.1.1 linguaggio di programmazione e linguaggio macchina¶
le istruzioni che un calcolatore segue per eserguire i compiti assegnati sono scritte in linguaggio macchina, che non è umanamente intelleggibile
i linguaggi di programmazione sono gli strumenti di scrittura umana delle istruzioni per il calcolatore
la traduzione delle istruzioni scritte in linguaggi di programmazione in istruzioni per il calcolatore è effettuata da appositi programmi
l’esecuzione di un programma corrisponde al momento in cui il calcolatore segue le istruzioni impartite
0.1.2 linguaggi intepretati o compilati¶
esistono due grandi categorie di linguaggi di programmazione:
linguaggi interpretati |
|---|
la traduzione del programma avviene automaticamente durante la sua esecuzione
le istruzioni sono lette e tradotte riga per riga, quindi spesso il programmatore può scrivere la riga successiva dopo aver osservato il risultato dell’istruzione precedente
il programma è in generale lento, perché la traduzione contestuale non è ottimizzata
pythonè un linguaggio di programmazione interpretato
linguaggi compilati |
|---|
la traduzione del programma avviene prima della sua esecuzione, tramite l’invocazione di istruzioni specifiche di compilazione
il programma va concepito nella sua interezza prima dell’esecuzione
le istruzioni vengono eseguite velocemente
CeC++sono esempi di linguaggi di programmazione compilati
0.1.3 C e C++¶
Cè un linguaggio di programmazione:imperativo, cioè che impartisce sequenze di istruzioni al calolatore
procedurale, cioè che permette di raggruppare istruzioni in procedure
C++è un linguaggio di programmazione:che estende il
C:un programma
Ccompila anche inC++la sintassi del
Cè valida anche inC++esistono concetti nuovi nel
C++esiste più libertà nel
C++
object oriented, cioè che permette di definire nuovi tipi di variabili all’interno dei programmi
vedremo che si tratta di un cambio di paradigma fondamentale
permette la programmazione template, che è una forma di generalizzazione delle istruzioni impartite al calcolatore
vedremo che porta alla creazione di molte librerie di utilità generale
esistono diverse versioni del linguaggio
C++: C++98 (che useremo noi), C++03, C++11 (che accenneremo), C++14, C++17
0.2 Un primo programma¶
0.2.1 il codice sorgente¶
la sequenza di istruzioni scritte nel linguaggio di programmazione sono salvate in un file di testo, che è solitamente chiamato codice sorgente
gli editor di testo dedicati alla programmazione contengono strumenti specifici che permettono di evidenziare la sintassi del codice e talvolta controllarne la grammatica ed ortografia
oltre alle istruzioni, in un codice sorgente si possono inserire commenti, che sono frasi ignorate durante la compilazione
i commenti in
Ciniziano con/*e terminano con*/:
/* questo è un commento */
ATTENZIONE: i simboli di apertura e chiusura di commenti non funzionano come parentesi
scrivere
/* /* */ */non è come scrivere( ( ) )
in
C++i commenti possono anche iniziare con//e terminano automaticamente a fine riga:// questo è un commento
0.2.2 uno scheletro vuoto¶
il programma più semplice e autoconsistente è costituito dalla sequenza di istruzioni relative alla funzione
mainogni programma deve contenere una ed una sola funzione chiamata
main, che viene eseguita dal calcolatore quando il programma viene lanciatoesistono due versioni della funzione
mainuna senza argomenti che corrisponde al caso in cui il programma sia eseguito da SHELL senza argomenti:
int main () { return 0 ; }
una con argomenti in ingresso che corrisponde al caso in cui il programma sia eseguito da SHELL con l’aggiuntda di argomenti mediante una frase scritta a linea di comando:
int main (int argc, char ** argv) { return 0 ; }
entrambe le versioni illustrate della funzione
mainimplementano un programma funzionante che, quando viene eseguito, restituisce alla SHELL un numero intero, chiamato exit statusper convenzione si sceglie di restituire il numero
0se tutto è andato bene, mentre un numero non nullo è usato per segnalare che ci sono stati problemi durante l’esecuzione (esistono codici di errori codificati, tuttavia il programmatore ha la libertà di aggiungerne o cambiarli)
suggerimenti |
|---|
si consiglia di svolgere tutti gli esercizi presentati in ogni lezione in una cartella dedicata, quindi, dopo aver aperto una SHELL:
> mkdir Lab2_Modulo1 > cd Lab2_Modulo1 > mkdir Lezione_01 > cd Lezione_01 > touch main_00.cpp
il comando
touchcrea un file vuoto, in questo caso con nomemain.cpp. Aprite quindi il file con il vostro editor preferito, scrivete il codice e salvateil nome del file che contiene il codice sorgente può essere scelto arbitrariamente. Noi useremo sempre il suffisso
.cppper i codici sorgenti che contengono la funzionemain(vedremo che il codice sorgente di un programma può essere spezzato in più file)
nello scrivere un programma, ogni volta che si apre una parentesi graffa la si chiuda immediatamente, per non dimenticarlo
non dimenticate le variabili di ritorno delle funzioni,
mainincluso
0.2.3 la prima compilazione¶
create un codice sorgente
main.cppcon lo scheletro vuoto descritto al paragrafo precedenteil sorgente va compilato perché possa essere eseguito dal calcolatore
per compilare il programma si utilizza il comando
c++, chiamato compilatore:> c++ -o main_00 main_00.cpp
l’argomento
-o main_00dice al compilatore di chiamare l’eseguibile con il nomemain_00
per eseguire il programma (nel caso di
mainsenza argomenti):> ./main_00 >
non succede nulla, infatti non ci sono istruzioni all’interno della funzione
mainl’istruzione
return 0non dice di scrivere a schermo0, ma di restituire alla SHELL il valore0(questo valore può essere intercettato ed utilizzato mediante i comandi di SHELL)
suggerimenti |
|---|
includete sempre all’inizio del codice sorgente un commento che contenga il comando di compilazione del programma
0.2.4 scrivere a schermo¶
oltre ai comandi fondamentali disponibili di default, il
C++offre insiemi di istruzioni dedicate allo svolgimento di specifici compiti, questi sono incapsulate in librerie (identificate da un nome comeiostream,cmath…)bisogna sempre dichiarare al programma che si vuole utilizzare una o più librerie (usando il comando
#include <nome-della-libreria>)per scrivere a schermo, si utilizza la libreria
iostreamche gestisce il flusso (stream) di informazione in input (i) ed output (o) durante l’esecuzione del programma:#include <iostream> int main (int argc, char ** argv) { std::cout << "42" << std::endl ; return 0 ; }
la linea
#include <iostream>dice al compilatore di utilizzare la libreriaiostreamil compilatore sa dove trovare le librerie standard tramite variabili di ambiente della SHELL
la variabile
cout(che abbrevia character output) rappresenta lo strumento di output; in questo caso, essendo quello standard (std::) si tratta dello schermola variabile
endlè la fine della linea, essendo quella standard è un accapoil simbolo
<<rappresenta l’operatore di redirezione, che sposta quello che sta alla propria destra verso sinistra. Quindi in questo caso primaendlviene incollato a42, quindi l’insieme dei due viene inviato allo schermo.
l’esecuzione del programma visualizzerà a schermo
42:> c++ -o main_01 main_01.cpp > ./main_01 42
0.2.5 il lavoro del compilatore¶
la compilazione di un programma di divide in tre fasi
preprocessing |
|---|
creazione del programma da compilare:
vengono eseguite le direttive date al preprocessore, sono le istruzioni che iniziano con il simbolo
#ad esempio, l’istruzione
#include <iostream>chiede al preprocessore di copiare al posto della linea stessa tutto il codice sorgente contenuto nella libreriaiostream
compilazione |
|---|
il compilatore vero e proprio entra in azione in questo stadio ed effettua:
controllo sintattico del programma
ad esempio,
itninvece diintdà errore
controllo grammaticale del programma
traduzione del codice sorgente in linguaggio macchina
ogni funzione, creata in linguaggio macchina, diventa un oggetto del compilatore
linking |
|---|
in questo ultimo passaggio, vengono connessi i vari oggetti del compilatore
nel nostro esempio, la parte pre-compilata delle librerie viene debitamente connessa alle chiamate presenti nella funzione
main
NOTA BENE: gli oggetti del compilatore non hanno a che fare con la programmazione ad oggetti, si tratta di uno sfortunato caso di omonimia
0.2.6 parametri passati a linea di comando¶
si possono passare informazioni al programma aggiungendo parametri a linea di comando
la SHELL passa alla funzione
mainla frase scritta dall’utente, sotto forma diarraydi stringhe di tipoCargcè il numero di elementi dell’arrayargvè l’array stesso
#include <iostream> int main (int argc, char ** argv) { std::cout << "42" << std::endl ; std::cout << "ecco il nome dell'eseguibile: " << argv[0] << "\n" ; return 0 ; }
0.2.7 parametri chiesti all’utente del programma¶
la liberia
<iostream>può essere anche utilizzata per leggere informazioni dalla tastiera#include <iostream> int main (int argc, char ** argv) { int numero = 0 ; std::cout << "inserisci un numero\n" ; std::cin >> numero ; std::cout << "hai inserito: " << numero << "\n" ; return 0 ; }
la tastiera è identificata da
std::cinl’operatore
>>trasferisce l’informazione dall’esterno verso il programma:
> ./main_03 inserisci un numero 4 hai inserito: 4
0.3 Le variabili¶
le informazioni sono manipolate dal programma sotto forma di variabili, che indicano zone di memoria del calcolatore riservate dal programma per la memorizzazione dell’informazione
diversi tipi di oggetti hanno bisogno di dimensioni differenti di memoria e di un formato diverso di scrittura
per ogni differente possibilità esiste un tipo associato in
C++, che contiene le informazioni di lunghezza e formattazionei principali tipi sono i seguenti:
tipo |
Keyword |
contenuto |
|---|---|---|
Boolean |
bool |
vero/falso |
Character |
char |
singoli caratteri |
Integer |
int |
numeri interi fra -32768 fino a 32767 |
Floating point (virgola mobile) |
float |
numeri razionali |
Double floating point |
double |
numeri razionali |
Valueless |
void |
nessun tipo |
0.3.1 la loro inizializzazione¶
le variabili si definiscono ed inizializzano utilizzando le keyword indicate in tabella precedente:
// definizione di due numeri interi int num1 = 0 ; int num2 = 3 ; // somma di due numeri interi int somma = num1 + num2 ; std::cout << "Somma: " << somma << std::endl ; // definizione di due numeri razionali float razionale1 = 3.1416 ; double razionale2 = 1.4142 ; // definizione di un carattere char lettera = 'à' ; // definizione di un valore booleano bool condizione = true ;
NOTA BENE: le variabili di tipo
charsono definite con valori indicati fra apici, non fra virgolette
suggerimenti |
|---|
non appena una variabile viene definita, assegnarle sempre un valore, tipicamente optando per una delle seguenti scelte:
si assegna un valore di default, che abbia senso nei calcoli a seguire;
si assegna un valore palesemte insensato, in modo che se ci si scorda di assegnare il valore corretto alla variabile, il programma non funzioni o dia risultati palesemente insensati;
definire una variabile per riga, per chiarezza di lettura;
dare nomi esplicativi alle variabili (e quindi anche sufficientemente lunghi).
0.3.2 l’attributo const¶
l’attributo
constpremesso ad una variabile indica che essa non può cambiare di valore durante l’esecuzione del programma.se nel codice sorgente si prova a modificare una variabile dichiarata
const, il compilatore si accorge di questo errore di grammatica di programmazione e non compila, restituendo un errore:> c++ -o main_05 main_05.cpp main_05.cpp:10:12: error: cannot assign to variable 'numerò with const-qualified type 'const int' numero = numero + 1 ; ~~~~~~ ^ main_05.cpp:9:15: note: variable 'numerò declared const here const int numero = 0 ; ~~~~~~~~~~^~~~~~~~~~ 1 error generated.
0.3.3 gli array di variabili¶
ad una variabile è associata una zona di memoria nella RAM, che è dove il calcolatore scrive la variabile durante le operazioni
in
C++è possibile definire una zona di memoria estesa, chiamata array, predisposta a contenere un elenco di variabili dello stesso tipo giustapposte in celle di memoria contigue// array di 5 numeri interi int num_array[5] ;
la dimensione dell’array, indicata fra parentesi nella definizione della variabile, non può essere una variabile (nemmeno
const), deve essere un numero scritto nel codice sorgente
le singole celle di memoria sono accessibili tramite l’operatore
operator[]applicato al nome della variabile, che si scrive utilizzando le parentesi quadre come nell’esempio che segue:num_array[0] = 3 ; num_array[1] = 6 ; num_array[2] = 9 ; num_array[3] = 11 ; num_array[4] = 131 ;
0.3.4 gli indici degli array¶
gli indici delle celle di memoria di un array lungo N partono a 0 e finiscono ad N-1
il compilatore non sempre si accorge che gli indici siano in questo intervallo
qualunque tentativo di leggere una zona di memoria all’esterno di questo intervallo può produrre un errore in fase di compilazione, oppure un comportamento inatteso del programma
provate, nel caso dell’array precedente, a includere queste istruzioni nel vostro programma:
int index = 4 ; std::cout << num_array[index + 1] << std::endl ;
NOTA BENE: si tratta di errori difficili da trovare, bisogna prestare molta attenzione agli indici di lettura degli array
0.3.5 la definizione di un array mediante il suo contenuto¶
un array può essere anche definito indicandone esplicitamente la lista degli elementi fra parentesi graffe:
float float_array[] = {2., 3.14} ; std::cout << float_array[0] << std::endl ; std::cout << float_array[1] << std::endl ;
0.3.6 il casting fra diversi tipi in C¶
il casting in
Cè la conversione fra diversi tipi di variabili numerichesiccome le medesime operazioni fra tipi diversi possono dare risultati differenti (provate a calcolare il valore della frazione 3/5 come rapporto fra due variabili
into come rapporto fra due variabilifloat), è importante sapere come convertire variabili in maniera esplicita, utilizzando la sintassi(type) numeroper convertire la variabilenumeronel tipotype:int numero_intero = 4 ; float numero_razionale = (float) numero_intero ;
0.3.7 il casting in C++¶
in
C++l’operazione di casting ha portata più ampia e può essere realizzato con operatori dedicati. Quello con la funzionalità equivalente al type cast delCè:float secondo_razionale = static_cast<float> (numero_intero) ;
NOTA BENE uno dei vantaggi di usare l’espressione
C++del cast è che questo è facilmente rintracciabile nel codice sorgente!
0.4 Gli operatori¶
Gli operatori predefiniti in
C++permettono di compiere operazioni fra variabiliPer ogni tipo di variabile, esistono operatori corrispondenti alle operazioni che si possono fare fra queste variabili
gli operatori si comportano alla stregua di funzioni, con variabili in ingresso e variabili di ritorno
tipicamente un operatore agisce su un singolo di tipo, quindi l’applicazione di operatori a più di un tipo implica un casting implicito fatto dal compilatore
0.4.1 l’operatore di assegnazione¶
attribuiscono il valore iniziale ad una variabile:
int numero = 5 ;
in questo caso, il tipo in ingresso è un
int(la variabile stessa è una sorta di argomento implicito dell’operatore)l’effetto dell’operatore è quello di assegnare alla variabile
numeroil valore che sta a destra del simbolo=il tipo in uscita è ancora
inted è il valore assegnato alla variabile
std::cout << (numero = 7) << std::endl ;
di conseguenza, le assegnazioni si possono fare in cascata:
int numero_2 = numero = 7 ;
anche per l’operatore di assegnazione si realizza il casting implicito:
float razionale = 5 ;
5è di tipoint, quindi viene prima convertito infloat(5.) e poi passato come argomento all’operatore di assegnazione
0.4.2 operatori aritmetici¶
corrispondono alle tipiche operazioni matematiche fra numeri interi o razionali
float R1 = 5. ; float R2 = 5. ; float R3 = R1 + R2 ; std::cout << R3 << std::endl ; R3 = R3 + 4.5 ; std::cout << R3 << std::endl ;
0.4.3 operatori aritmetici composti con assegnazione¶
gli operatori aritmetici esistono anche composti con l’operatore di assegnazione
R3 += 2.1 ; std::cout << R3 << std::endl ;
l’operazione precedente è equivalente a equivalente a
R3 = R3 + 2.1 ;
operatore
op. composto
operazione
++=addizione
--=sottrazione
**=moltiplicazione
//=divisione
%%=resto della divisione tra interi
0.4.4 operatori di incremento¶
L’incremento o decremento unitario di una variabile si può ottenere anche con operaori dedicati:
operatore
operazione
++incremento unitario
--decremento unitario
l’operatore agisce direttamente sulla variabile al quale viene applicato, similmente agli operatori composti:
int num = 5 ; ++num ; std::cout << num << std::endl ; --num ; std::cout << num << std::endl ;
0.4.5 pre-incremento e post-incremento¶
ciascun operatore esiste in due versioni:
pre-incremento o pre-decremento: la variabile a cui viene applicato viene modificata dall’operatore prima dell’esecuzione di eventuali altre operazioni che accadono in quella linea (
++num,--num), quindi l’operatore restituisce la variabile stessapost-incremento o post-decremento: la variabile a cui viene applicato viene modificata dall’operatore dopo dell’esecuzione di eventuali altre operazioni che accadono in quella linea (
num++,num--)
int num1 = 5 ; std::cout << ++num1 << std::endl ; int num2 = 5 ; std::cout << num2++ << std::endl ; std::cout << num2 << std::endl ;
gli operatori di post-incremento e post-decremento creano una copia della variabile alla quale sono applicati, incrementano la variabile e restituiscono la copia (che non è stata incrementata)
di conseguenza, gli operatori di post-incremento e post-decremento sono più lenti di quelli di pre-incremento e pre-decremento e richiedono che sia possibile creare una copia della variabile alla quale sono applicati
gli operatori di incremento vengono tipicamente utilizzati per aumentare o diminuire il valore delle variabili indice dei cicli
0.4.6 operatori relazionali¶
gli operatori relazionali confrontano tra loro i valori di due variabili
prendono in ingresso due variabili e restituiscono un valore booleano che indica se la relazione è soddisfatta o meno
operatore
operazione
==uguaglianza
!=non uguaglianza
<minore di
<=minore o uguale
>maggiore di
>=maggiore o uguale
NOTA BENE: l’operatore di uguaglianza ha due segni
=nel nome, perché l’operatore con un solo=assegna il valore di destra alla variabile di sinistra. La confusione tra i due operatori è una frequente sorgente di errori!
0.4.7 operatori logici¶
gli operatori logici codificano le relazioni fra variabili booleane:
operatore
operazione
&&and
\|\|or
!not
NOTA BENE: spesso ha luogo casting implicito fra variabili intere e booleane: in questo caso lo
0risulta falso, mentre ogni altro valore intero risulta vero
0.4.8 le precedenze fra operatori¶
se in una singola linea di un codice sorgente vengono effettuate diverse operazioni, il calcolatore le esegue da destra verso sinistra, rispettando l’ordine imposto da eventuali parentesi e una serie di regole di precedenza
ecco una tabella ridotta alle operazioni più comuni, gli operatori nelle righe più in alto hanno precedenza rispetto a quelli delle righe sottostanti
categorie di priorità |
|---|
|
|
|
|
|
|
|
|
|
la lista completa delle precedenze si trova qui
0.5 Le strutture di controllo¶
Le strutture di controllo sono il metodo che si utilizza nei linguaggi di programmazione procedurali per gestire il flusso di istruzioni che il calcolatore deve eseguire. Esistono tre tipi di strutture di controllo:
sequenza: si tratta della configurazione di default: le istruzioni si susseguono una dopo l’altra
selezione: a seconda che una condizione sia o meno soddisfatta, il calcolatore sceglie di eseguire diverse istruzioni
ciclo: un insieme di istruzioni viene ripetuto un certo numero di volte, in funzione di un algoritmo che decide quando l’iterazione è terminata
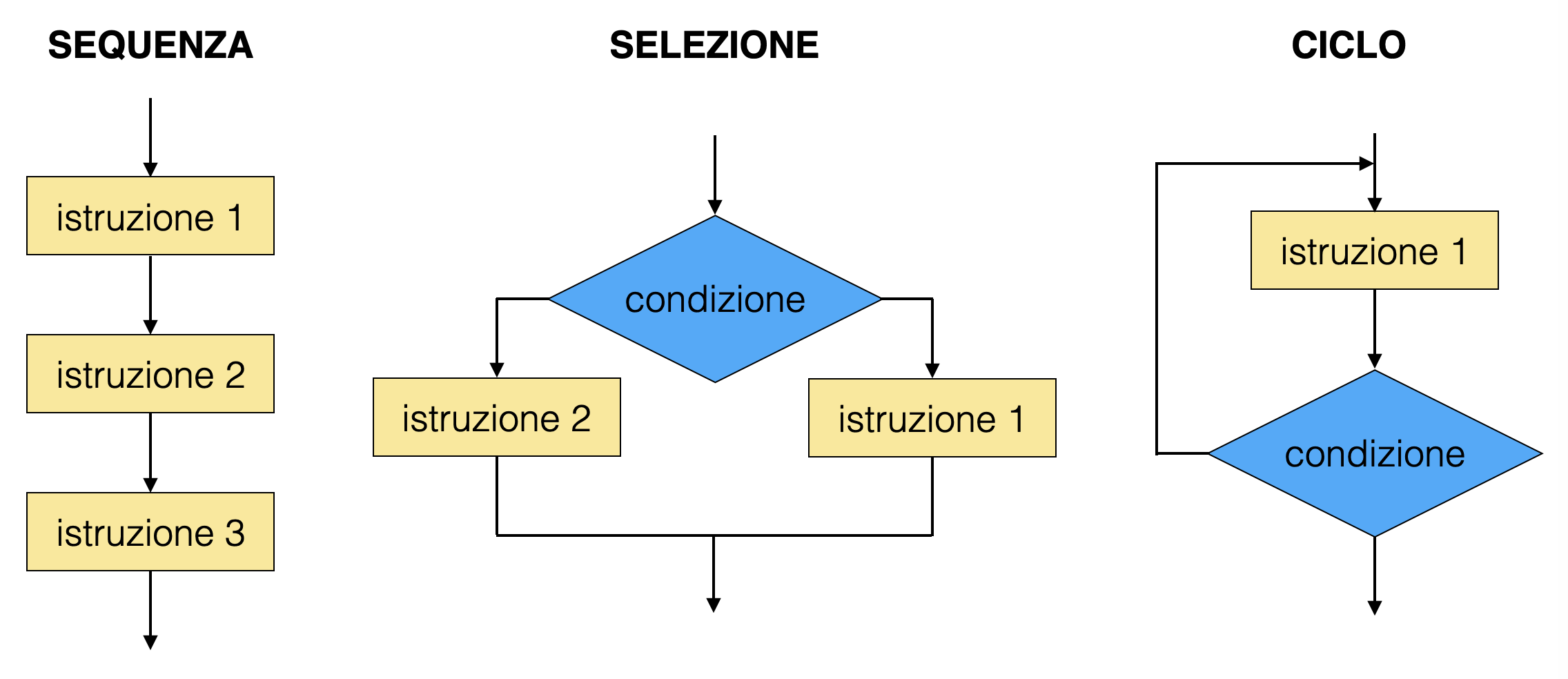
0.5.1 gli scope¶
nel codice sorgente diverse istruzioni vengono raggruppate in insiemi chiamati scope, delimitati da parentesi graffe
le variabili definite all’interno di uno scope rimangono definite solamente fino alla chiusura dello scope e vengono automaticamente rimosse alla chiusura della parentesi graffa
singole istruzioni all’interno di una struttura di controllo possono essere sostituite da un intero scope
0.5.2 if ... else¶
la sequenza
if (condizione) {scope} else {scope alternativo}realizza una selezione binaria, nella quale una istruzione o uno scope di istruzioni vengono eseguiti nel caso in cui venga soddisfatta una condizione booleanaopzionalmente, uno scope alternativo può essere eseguito nel caso in cui la condizione risulti falsa
int num1 = 5 ; if (num1 % 2 == 0) { std::cout << num1 << " è pari\n" ; } else { std::cout << num1 << " è dispari\n" ; }
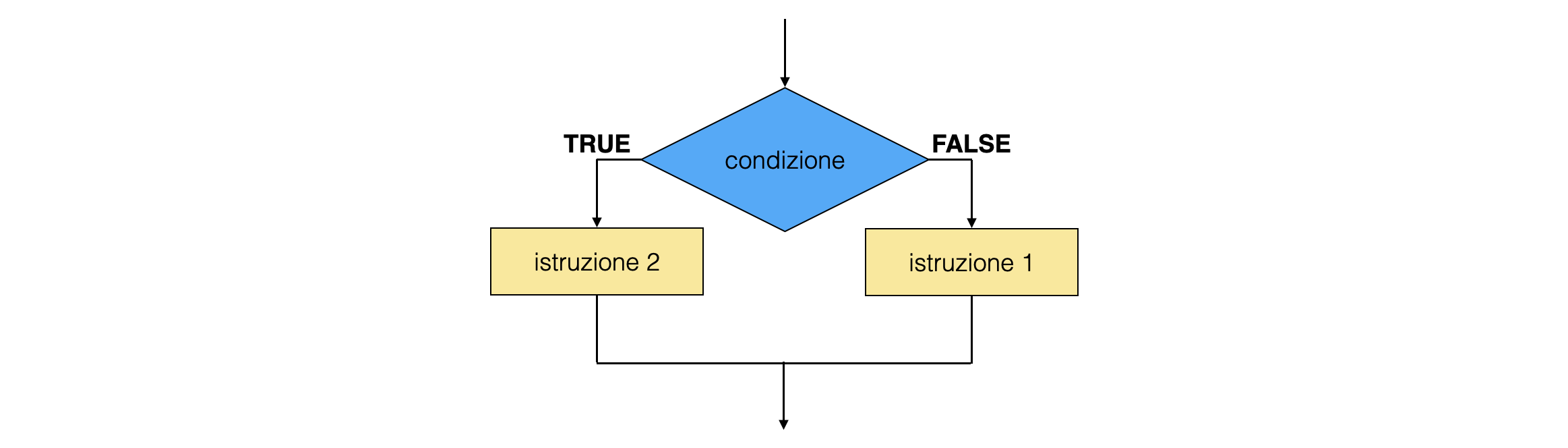
0.5.3 switch ¶
la sequenza
switch ... case ... defaultrealizza una selezione fra molte opzioni, basata sul valore di una variabile:int num2 = 2 ; switch (num2) { case 1: // blocco di istruzioni std::cout << "uno\n" ; break; case 2: // blocco di istruzioni std::cout << "due\n" ; break; default: std::cout << "altri numeri\n" ; // blocco di istruzioni }
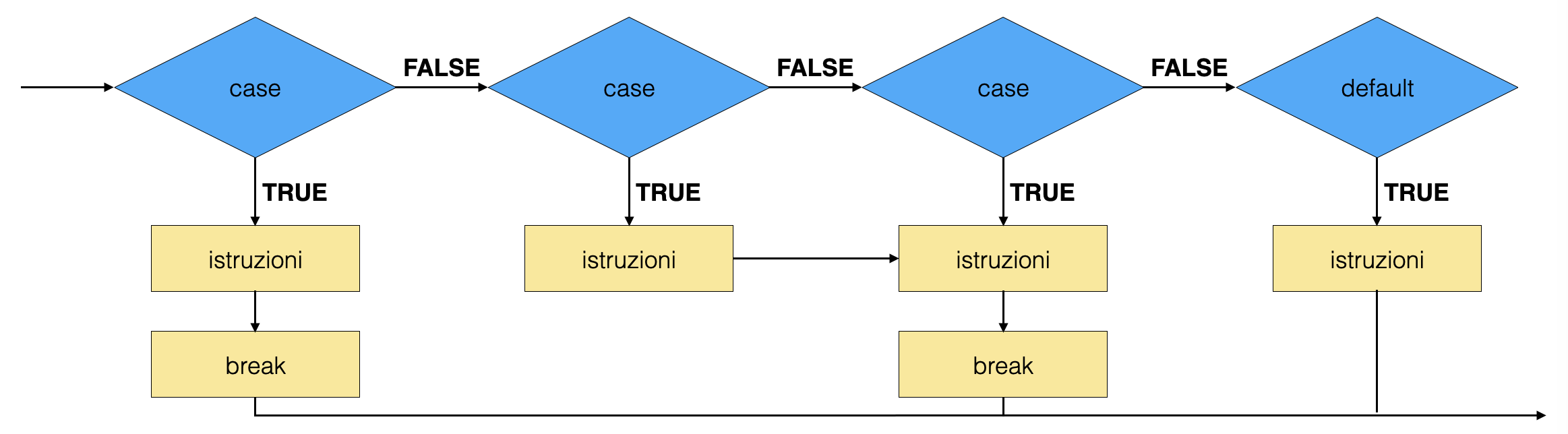
nella struttura di controllo
switch (espressione)vengono eseguite le istruzioni che stanno sotto la lineacasetale per cuiespressioneè uguale al valore riportato dopo la parola chiavecaseper evitare che vengano eseguite anche le istruzioni riportate dopo i
caseseguenti, solitamente si inserisce in ogni blocco di istruzioni il comandobreak, che interrompe l’esecuzione dello scopela situazione in cui le istruzioni eseguite non siano soltanto quelle del
casecorrispondente al valore diespressioneprende il nome di fallthroughil comando
breakpuò essere utilizzato anche per interrompere l’esecuzione di un ciclola presenza di un
breaknon è obbligatoria
oltre ai vari
case, si può aggiungere un ulteriore caso, che contiene istruzioni da svolgere nell’evenienza in cui nessuno deicasevenga soddisfatto, che viene etichettato con la parola chiavedefaultil caso di
defaultnon è obbligatorio
0.5.4 il ciclo for¶
la struttura di controllo
for ()è un modo di implementare la struttura di controllo a ciclo, tipicamente nel caso in cui al ciclo sia associato un conteggionella parentesi che segue il comando
forsono solitamente riportate tre istruzioni, separati da un punto e virgola:inizializzazione: dove viene inizializzata (e talvolta definita) una variabile che conta il numero di cicli, detta contatore
controllo: dove si verifica se il numero di cicli abbia oltrepassato una determinata soglia
incremento: dove si incrementa il contatore
int N = 10 ; for (int i = 0 ; i < N ; ++i) { std::cout << "il doppio di " << i << " vale: " << 2 * i << std::endl ; }
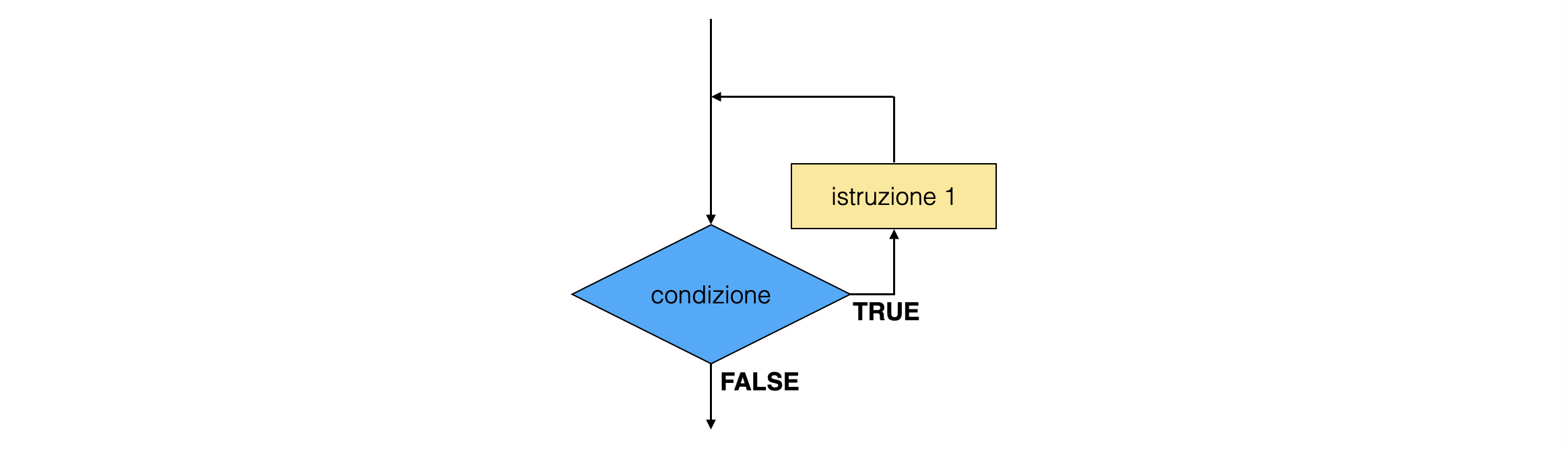
le variabili definite fra parentesi rimangono definite soltanto all’interno dello scope del ciclo
l’operazione di controllo viene compiuta prima di effettuare nell’iterazione corrispondente
l’operazione di incremento viene compiuta dopo che è stata effettuata l’iterazione corrispondente
c’è molta libertà nella scrittura di un ciclo
for: i tre campi fra parentesi possono anche essere vuoti ed il programma compilautilizzare una scrittura non ortodossa del ciclo
forpuò portare ad errori logici nel programma, che possono condurre a risultati inaffidabili in fase di esecuzione
0.5.5 il ciclo while¶
la struttura di controllo
while ()consente di implementare un ciclo fintanto che una condizione risulta veranella parentesi che segue l’istruzione
whileè codificata un’affermazione da verificare (condizione); se l’affermazione è vera (condizione soddisfatta), lo scope del ciclo viene effettuatoint N = 10 ; int i = 0 ; while (i < N) { std::cout << "il doppio di " << i << " vale: " << 2 * i << std::endl ; ++i ; }
il controllo sulla condizione viene effettuato prima dell’esecuzione dell’iterazione corrispondente
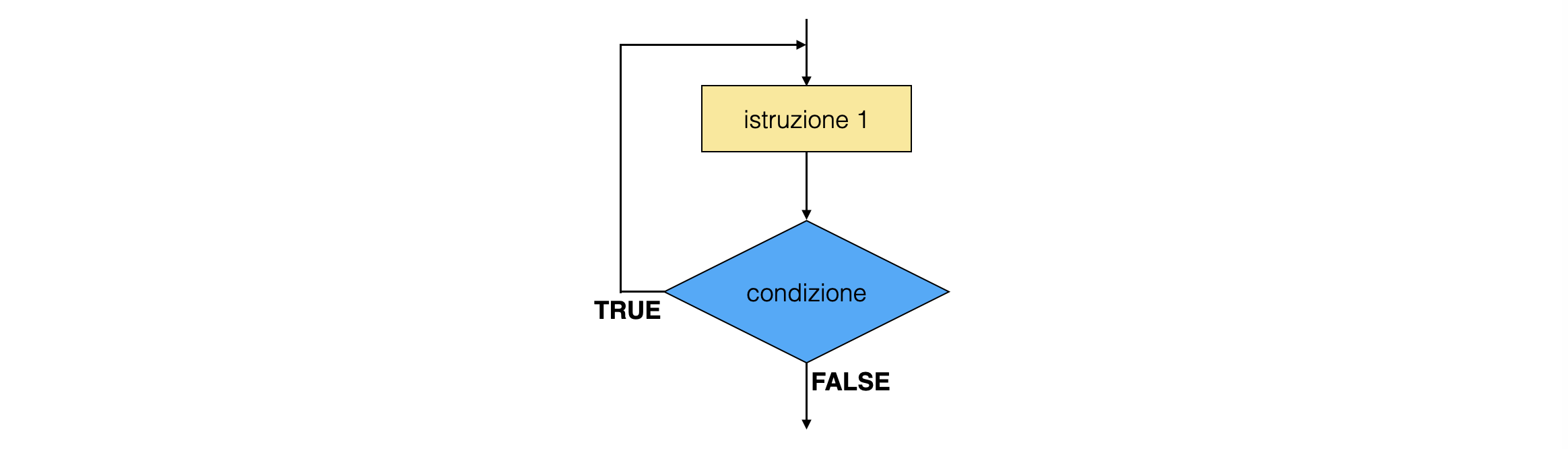
0.5.6 il ciclo do ... while¶
talvolta conviene che la condizione di proseguimento del ciclo venga verificata dopo l’esecuzione dello scope (ad esempio quando, prima della prima esecuzione dello scope, non ha senso effettuare il controllo)
per ottenere questo comportamento, si utilizza la sintassi
do { ... } while ()do { std::cout << "il doppio di " << i << " vale: " << 2 * i << std::endl ; ++i ; } while (i < 2 * N) ;
0.5.7 l’interruzione di un ciclo¶
oltre a terminare quando la condizione di controllo diventa falsa, l’esecuzione di un ciclo può essere interrotta con due comandi:
l’istruzione
breakche interrompe l’esecuzione dell’iterazione ed esce dal ciclol’istruzione
continueche interrompe l’esecuzione dell’iterazione e passa a quella successiva
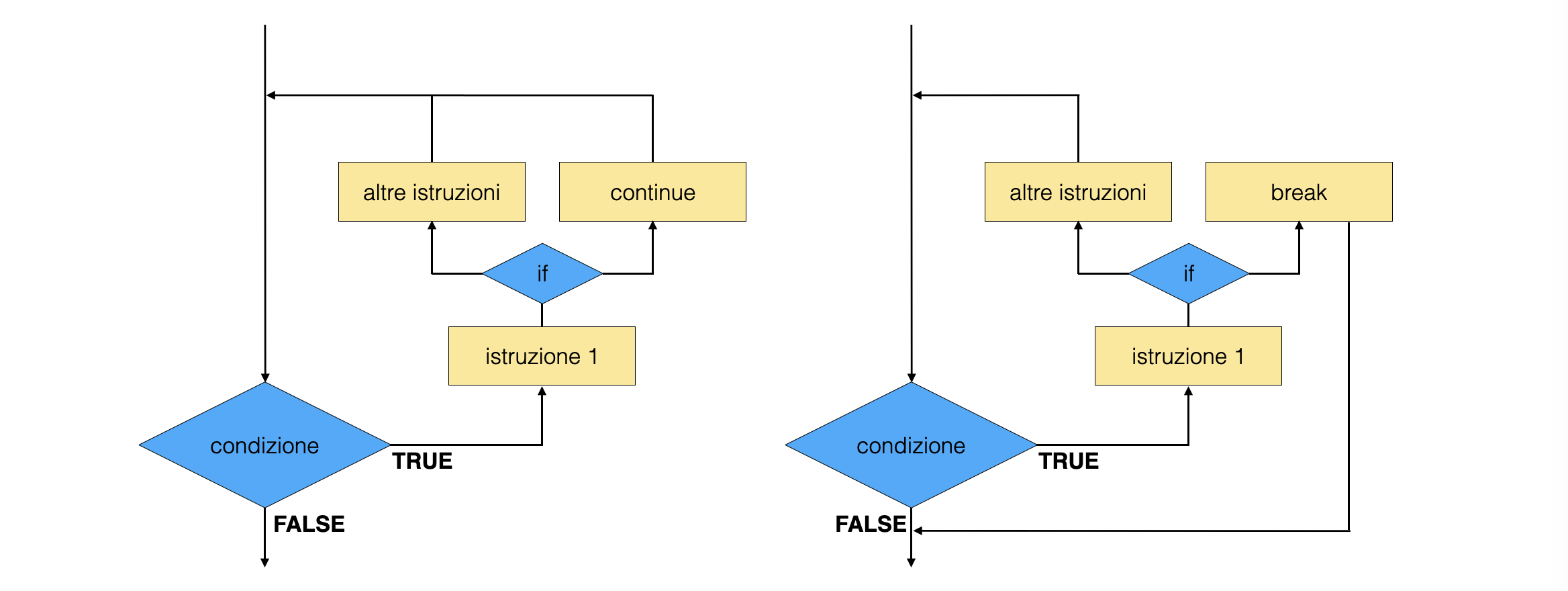
l’esistenza di questi comandi permette di aggiungere controlli aggiuntivi oltre alla condizione presente nella parentesi delle istruzioni
forewhile, rendendo la programmazione più elasticaquesto permette addirittura di lasciare i controlli nelle parentesi vuoti ed effettuarli direttamente nello scope del ciclo
aumenta considerevolmente il rischio che il ciclo non termini mai
0.6 Le funzioni¶
insiemi di istruzioni che svolgono un compito preciso e spesso ripetuto all’interno di uno o più programmi vengono solitamente raggruppate in funzioni, che si utilizzano come un singolo comando
le funzioni hanno un nome, una o più variabili in ingresso e restituiscono una sola variabile, con il comando
return
0.6.1 un primo esempio¶
le funzioni vanno definite prima di essere chiamate e possono essere simultaneamente definite e implementate (come nel caso sottostante)
int raddoppia (int input_value) { return 2 * input_value ; } int main (int argc, char ** argv) { for (int i = 0 ; i < 5 ; ++i) { std::cout << "il doppio di " << i << " vale: " << raddoppia (i) << std::endl ; } return 0 ; }
0.6.2 funzioni senza tipo di ritorno¶
una funzione che non restituisce alcun valore si definisce con la parola chiave
void(indicatore del tipo di ritorno invece diint,float…) ed al suo interno l’istruzionereturnè immediatamente seguita da una virgolaint raddoppia (int input_value) { return 2 * input_value ; } void scriviAschermo (int input_value) { std::cout << "ecco il numero da scrivere: " << input_value << std::endl ; return ; } int main (int argc, char ** argv) { for (int i = 0 ; i < 5 ; ++i) { scriviAschermo (raddoppia (i)) ; } return 0 ; }
0.6.3 funzioni ed omonimia¶
il nome di una funzione, insieme ai suoi tipi in ingresso, la identifica univocamente
nello stesso programma non possono esistere due funzioni diverse con lo stesso nome e gli stessi tipi in ingresso
funzioni con lo stesso nome, ma con tipi in ingresso diversi, possono invece coesistere: questa proprietà del
C++si chiama overloadingint raddoppia (int input_value) { return 2 * input_value ; } float raddoppia (float input_value) { return 2 * input_value ; }
0.6.4 il prototipo di una funzione e la sua implementazione¶
definire una funzione prima di essere chiamata è necessario per permettere il controllo grammaticale del codice sorgente da parte del compilatore
per effettuare il controllo grammaticale, al compilatore è sufficiente conoscere il nome della funzione, la variabili in ingresso e quelle in uscita
è quindi lecito anticipare questa informazione sotto forma di prototipo, posticipando la scrittura dell’implementazione della funzione:
int raddoppia (int) ; int main (int argc, char ** argv) { for (int i = 0 ; i < 5 ; ++i) { std::cout << "il doppio di " << i << " vale: " << raddoppia (i) << std::endl ; } return 0 ; } int raddoppia (int input_value) { return 2 * input_value ; }
ciò permette di lasciare più in evidenza la funzione
mainrispetto alle altrenella scrittura del prototipo, non è necessario indicare il nome delle variabili (ma è permesso)
0.6.5 valori di default degli argomenti di una funzione¶
nel prototipo, oppure nell’implementazione, si possono assegnare valori di default alle variabili, questi saranno i valori utilizzati dalla funzione per quella variabile nel caso in cui il valore non venga passato al momento della chiamata della funzione
int raddoppia (int input_value = 0) { return 2 * input_value ; }
il valore di default deve essere attribuito solamente in uno dei due luoghi
in caso di funzioni con più variabili in ingresso, se ad una variabile viene assegnato un valore di default anche le variabili seguenti devono possederlo, per evitare situazioni di ambiguità
0.6.6 l’esportazione delle funzioni in librerie¶
funzioni che vengono utilizzate in più di un programma
mainpossono essere scritte in un file diverso, in modo che non sia necessario riscriverle ogni voltaogni funzione, dopo essere stata compilata, diventa un oggetto del compilatore
dopo la compilazione, il linker (che è il terzo passaggio della compilazione) connette le varie funzioni per costruire l’eseguibile finale
per permettere al compilatore di controllare la grammatica in fase di compilazione, è sempre necessario mettere nel codice sorgente del
mainil prototipo delle funzioniquesta struttura viene realizzata tipicamente con tre file:
libreria.h,libreria.cc,main.cpp
0.6.7 il file libreria.h¶
libreria.h: è il file che contiene il codice sorgente dei prototipi delle altre funzioni#ifndef libreria_h #define libreria_h int raddoppia (int) ; #endif
le linee che iniziano con
#sono istruzioni al preprocessore, si tratta del controllo di una condizione: se non è definita una variabile (#ifndef) con il nomelibreria_h, si considera tutto quello che segue fino ad#endifquesto permette di non definire due volte il prototipo di una funzione, che genererebbe un errore di compilazione
chiamato in generale header file
0.6.8 il file libreria.cc¶
libreria.cc: è il file che contiene il codice sorgente delle funzioni secondarie#include "libreria.h" int raddoppia (int input_value) { return 2 * input_value ; }
il codice sorgente include
libreria.hper ereditare tutte le definizioni e gli altri#includeche stanno al suo interno
0.6.9 il file main.cpp¶
main.cpp: è il file che contiene il codice sorgente della funzionemain#include <iostream> #include "libreria.h" int main (int argc, char ** argv) { for (int i = 0 ; i < 5 ; ++i) { std::cout << "il doppio di " << i << " vale: " << raddoppia (i) << std::endl ; } return 0 ; }
il codice sorgente include
libreria.hper ereditare tutte le definizioni e gli altri#includeche stanno al suo internoil file
libreria.ccnon viene mai incluso, ma va indicato nel comando di compilazione:> c++ -o main_16 libreria.cc main_16.cpp
NOTA BENE i file indicati fra parentesi angolate nelle istruzioni
#includevengono cercati, dal preprocessore, in cartelle predefinitese il nome del file è racchiuso tra doppi apici il file viene dapprima cercato nella cartella in cui si sta compilando e successivamente in cartelle predefinite
0.6.10 librerie in C++¶
si possono creare ed includere più di una libreria in un programma
le librerie di
C++funzionano in questo modo, con i codici sorgente delle librerie spesso già compilati ed il file da includere indicato fra parentesi angolate, come ad esempio#include <iostream>
suggerimenti |
|---|
è utile organizzare le proprie librerie per funzionalità, sia per strutturazione logica del proprio programma che per decidere che cosa includere e compilare in ogni programma
l’utilizzo di una funzione comporta rallentamento nel programma, perché richiede al calcolatore di cercare in memoria la funzione di passarle gli argomenti e di recuperarne l’output, che sono operazioni aggiuntive
0.6.11 le funzioni inline¶
si può utilizzare la parola chiave
inline, per chiedere al compilatore di sostituire la funzione con la sua implementazione.questo si fa (è vantaggioso) solo per funzioni piccole per cui il tempo di esecuzione delle operazioni codificate è confrontabile con il tempo di chiamata di una funzione non
inline#ifndef libreria_h #define libreria_h inline int raddoppia (int input_value) { return 2 * input_value ; } #endif
in questo caso, la funzione va definita prima del
main, quindi nel file.hil compilatore può decidere di ignorare la parola chiave
inlinequando non sono soddisfatti determinati criteri (quindi l’istruzioneinlineè una richiesta o proposta fatta al compilatore, non un comando)
0.6.12 funzioni matematiche¶
la libreria
cmathoffre un’utile estensione delle operazioni matematicheper poterla utilizzare, bisogna includerne il file
.hcorrispondente:#include <cmath>la libreria contiene funzioni e variabili notevoli
la lista delle funzioni notevoli si trova qui, contiene funzioni trigonometriche, funzioni di potenza, iperboliche…
0.6.13 un esempio: radice quadrata ed elevamento a potenza¶
un esempio di utilizzo delle funzioni presenti in
cmathriguarda l’elevamento a potenza e la radice quadrata:float num = 4.5 ; std::cout << "quadrato di " << num << ": " << pow (num, 2) << "\n" ; num = pow (num, 2) ; std::cout << "radice di " << num << ": " << sqrt (num) << "\n" ; std::cout << "radice di " << num << ": " << pow (num, 0.5) << "\n" ;
la funzione
powha come primo argomento la base della potenza, come secondo argomento il suo esponenteutiilzzare l’espressione
num * numinvece dipow (num, 2)
è meno dispendioso in termini di tempo di esecuzione
0.6.14 accesso all’orologio del computer¶
un’altra libreria di uso frequente
ctimel’istruzione
clock ()restituisce il tempo di calcolo del processore consumato dal programma, espresso in cicli di calcolola frequenza dei cicli di calcolo è disponibile nella variabile
CLOCKS_PER_SEC
l’istruzione
ctime ()resituisce il tempo trascorso a partire dal primo gennaio 1970
0.6.15 un test di performance¶
se volessimo confrontare la velocità di esecuzione della funzione
pow (x, 2)rispetto all’operazionex * xpotremmo ripetere entrambe le operazioni molte (N) volte e misurare il tempo di calcolo nei due casi:double start = (double) clock () / CLOCKS_PER_SEC ; for (double i = 0; i < N; ++i) { test += pow (i, 2) ; } double stop = (double) clock () / CLOCKS_PER_SEC ; std::cout << "tempo di esecuzione per pow: " << stop - start << " secondi\n" ; start = (double) clock () / CLOCKS_PER_SEC ; for (double i = 0; i < N; ++i) { test += i * i ; } stop = (double) clock () / CLOCKS_PER_SEC ; std::cout << "tempo di esecuzione per i*i: " << stop - start << " secondi\n" ;
si otterrebbe un risultato di questo tipo:
tempo di esecuzione per pow: 30.2506 secondi
tempo di esecuzione per i*i: 3.91943 secondi
0.7 Direttive al preprocessore¶
l’insieme di istruzioni che iniziano con il simbolo
#si chiamano direttive al preprocessore perché vengono lette ed interpretate prima della fase di compilazionesi tratta di istruzioni che non riguardano la fase di compilazione del programma, quindi macro e variabili del preprocessore sono concetti diversi rispetto alle funzioni e variabili di
C++
0.7.1 la direttiva #include¶
come abbiamo già visto, questa istruzione viene utilizzata quando si scrivono librerie di funzioni in un file separato da quello che contiene il codice sorgente del
mainprogramseguendo questa direttiva, il preprocessore sostituisce alla linea l’intero file riportato dopo
#include
0.7.2 variabili del preprocessore¶
la direttiva
#definedefinisce variabili del preprocessoreviene estensivamente utilizzata, unitamente al controllo booleano
#ifndef(se non è definita), per impedire la doppia definizione del prototipo di una funzione e per impedire che si crei un circolo infinito di istruzioni#include:#ifndef libreria_h #define libreria_h int raddoppia (int) ; #endif
è invalso nell’uso utilizzare
#defineanche in sostituzione di variabili delC++#define NUMERO 150si tratta di una cattiva pratica di programmazione, perché può portare a comportamenti inattesi del programma (inclusi problemi di compilazione) e rende difficile la fattorizzazione del codice sorgente
in questo caso,
NUMEROnon è una variabile delC++, bensì il preprocessore sostituisce il testoNUMEROcon il testo100nel programma prima della compilazionequando si utilizzano questi metodi poco ortodossi, è buona regola utilizzare prassi sintattiche che differenzino chiaramente le effettive variabili del
C++dalle sostituzioni di testo del preprocessore, ad esempio scrivendone il nome interamente in caratteri maiuscoli
0.7.3 le macro del preprocessore¶
si possono anche definire macro del preprocessore, che sono espressioni che richiamano in forma il comportamento delle funzioni del
C++#define quadrato(a) a*autilizzare le macro del processore come funzioni può produrre disastri, questo programma:
int main (int argc, char ** argv) { double numero = 3. ; double risposta = quadrato (numero + 1.) ; std::cout << "Il quadrato di " << numero + 1. << " vale " << risposta << "\n" ; return 0 ; }
produce come output:
Il quadrato di 4 vale 7
infatti la sostituzione operata dal preprocessore genera questa istruzione
double risposta = numero + 1. * numero + 1. ;
0.8 La scrittura del proprio programma¶
perché un codice sorgente compili, bisogna rispettare sintassi e grammatica del
C++perché un programma funzioni, bisogna evitare errori logici nell’uso del
C++e nella funzionalità degli algoritmiperché un codice sorgente sia leggibile, è buona cosa seguire regole aggiuntive di buon senso nella scrittura
0.8.1 la nomenclatura di variabili e funzioni¶
scegliete nomi di funzioni e variabili lunghi ed autoesplicativi
scegliete nomi che riguardino il ruolo effettivo di variabili e funzioni: ad esempio, se una variabile o una funzione servono nel programma per ottenere un determinato calcolo, ma abbiano funzionalità più ampia, il loro nome deve riflettere l’effettiva funzionalità
scegliete un sistema consistente di nomenclatura, ad esempio:
le funzioni iniziano con lettere minuscole, le variabili con lettere maiuscole
nei nomi compposti da più parole, si divide il nome con un
_(e.g.calcola_media), oppure rendendo maiuscola ogni parola all’interno (e.g.calcolaMedia)
0.8.2 la dimensione degli scope¶
scegliete di scrivere scope piccoli: se il numero di istruzioni in uno scope è molto alto, spezzatelo in sotto-gruppi tramite funzioni
una numero indicativo di istruzioni oltre il quale pensare se spezzare lo scope in funzioni è 7
0.8.3 l’utilizzo dei commenti nel codice sorgente¶
molti commenti nel codice sorgente aiutano a capire cosa facciano funzioni e variabili, descrivendo il loro contenuto o la loro funzionalità
i commenti possono essere utilizzati per chiarire che cosa sta succedendo nel codice sorgente
la spiegazione di eventuali formule utilizzate, oppure il link a pagine web di riferimento, possono essere inseriti nei commenti
nel caso di scope molto lunghi, per cui la chiusura di parentesi graffe non si vede insieme all’apertura, si possono usare commenti per ricordare al lettore quale scope sia chiuso da una graffa:
int main (int argc, char ** argv) { for (int i1 = 0 ; i1 < 100 ; ++i1) { /* tante istruzioni che si susseguono */ } // ciclo su i1 return 0 ; }
0.8.4 l’indentazione del codice sorgente¶
indentare il codice sorgente coerentemente aiuta enormemente la lettura del codice sorgente
tutte le istruzioni di uno stesso scope devono inizare alla medesima colonna
quando si apre uno scope, le istruzioni devono inziare in posizione rientrata rispetto allo scope precedente: scegliete una regola (ad es. 2 colonne) ed attenetevi rigorosamente a quella
imparate ad usare con cognizione di causa il tasto
TAB, oppure non utilizzatelo
decidete se aprire le parentesi graffe alla fine di una linea, oppure dopo essere andati accapo
non chiudete parentesi graffe su una linea in cui ci sono istruzioni
0.8.5 la fattorizzazione di un programma¶
molto spesso pezzi di codice sorgente vengono riciclati copiandoli da programmi vecchi ed incollandoli in programmi nuovi
per facilitare questa operazione e per rendere il codice sorgente più comprensibile, è buona norma mantenere il più vicino possible tutte le istruzioni relative ad un medesimo blocco logico del programma
definire le variabili appena prima che vengano utilizzate (cioè NON tutte all’inizio del programma)
NON sparpagliare per il programma istruzioni che logicamente si susseguono
0.8.6 dettagli¶
il
C++distingue maiuscole da minuscole, quindinumeNumsono due variabili diverseil
C++non riconosce caratteri speciali come lettere accentate, quindi non usatele nei codici sorgenteesistono caratteri riservati al
C++, come le virgolette, gli apici, o il backslash: nell’output a schermo evitate di utilizzarli, oppure fateli precedere con il carattere\\, che dice al compilatore di non utilizzare il carattere successivo come carattere riservato
0.8.7 unit testing¶
quando si scrive un nuovo programma, è utile compilare il codice sorgente molto spesso
ad ogni passaggio importante del programma, fate uno unit test, cioè test di compilazione ed esecuzione
scrivere la funzione
mainvuota è un passaggio importante (una unit da testare)includere una libreria è una unit da testare
aggiungere la definizione di una variabile rilevante per il programma è una unit da testare
aggiungere una struttura di controllo vuota, cioè ancora prima di avere scritto istruzioni all’interno, è una unit da testare
procedendo in questo modo, si semplifica molto l’identificazione delle cause di errori, perché sono tipicamente da ricercare soltanto nelle ultime aggiunte al codice sorgente
in caso di programmi molto complessi, è buona pratica preparare tante versioni della funzione
main, dove ciascuna fa da test di un aspetto specifico del programma, ad esempio una funzionemainper fare il test di ogni libreria creata
0.9 Le opzioni di compilazione¶
durante la compilazione di un codice sorgente, il compilatore (
c++) prende in ingresso diversi parametri. Alcuni sono elencati qui:parametro
ruolo
*.cc,*.cppcodice sorgente dell’implementazione: deve esserci una sola funzione
main-o eseguibilenome da assegnare all’eseguibile: valore di default è
a.out-O0compilazione veloce e non ottimizzata, esecuzione lenta
-O2compilazione ottimizzata e lenta, esecuzione più veloce
-O3compilazione ottimizzata e lenta, esecuzione più veloce
-Wallaccende tutti i Warning: il compilatore avvisa in caso di problemi sospetti
-Werrortrasforma Warning in errori: il compilatore non compila se ci sono Warning
provate a confrontare l’uso di
pow (x, 2)conx * xa diversi livelli di ottimizzazione: che cosa cambia?una lista completa di opzioni di compilazione si trova qui
0.9.1 il caso di librerie non di default¶
nel caso si utilizzino librerie non di default, si può istruire il compilatore riguardo alla loro posizione nel computer:
parametro
ruolo
-l[linalg]nome (*) della libreria precompilata (oggetto del compilatore) da linkare al programma
-L[/path/to/shared-libraries]la cartella dove stanno le librerie da linkare
-I[/path/to/header-files]dove stanno gli header file da includere
(*) il nome della libreria deve essere linalg.dll in Windows, liblinalg.so su Unix-like (e.g. Linux), linalg.dylib su MacOSX
spesso (come vedremo per ROOT) pacchetti esterni forniscono anche un comando che prepara queste opzioni per il compilatore
0.10 Gli errori di compilazione¶
in caso di errore di compilazione, il compilatore mostra a schemo la descrizione degli errori che ha riscontrato
il messaggio di errore è solitamente utile a capire il problema:
> c++ -o main_05 main_05.cpp main_05.cpp:10:12: error: cannot assign to variable 'numerò with const-qualified type 'const int' numero = numero + 1 ; ~~~~~~ ^ main_05.cpp:9:15: note: variable 'numerò declared const here const int numero = 0 ; ~~~~~~~~~~^~~~~~~~~~ 1 error generated.
in questo caso, il compilatore indica il file con il codice sorgente problematico, la linea alla quale ha trovato un errore e la ragione per la quale ha ritenuto che ci fosse un problema
spesso un singolo errore genera altri errori in cascata,
quindi è consigliato risolvere gli errori uno per uno, iniziando dal primo che si trova